Difference between revisions of "License Clearance Tool - Description and Documentation"
| Line 1: | Line 1: | ||
| − | {| class=" | + | {| class="floatright" |
| [[File:LCT logo 813x285.png|600px|LCT logo]] | | [[File:LCT logo 813x285.png|600px|LCT logo]] | ||
|- style="text-align: center;" | |- style="text-align: center;" | ||
Revision as of 12:06, 1 June 2021
| lct.ni4os.eu |
Purpose
This tool is the output for Task T4.4 that aims to mainstream concrete certification standards, tools and mechanisms for open research data management and certification schemes for data repositories, aligning with activities and results of INFRAEOSC-5c. It targets both data-intensive RDM (through cloud compute) and the curation and handling of the long tail of science with the aim of establishing consolidated models of RDM activities in the target countries. Building on the work undertaken in T4.2 and T4.3, this task delivers a certification tool for supporting trustworthiness of repositories and ensuring their FAIRness in a standardised and interoperable fashion, with the objective to support the onboarding of repositories to EOSC.
Newly produced datasets, but mostly the creation of derivative data or media works, i.e. for purposes like content creation, service delivery or process automation, is often accompanied by legal uncertainty about usage rights and high costs in the clearance of licensing issues. NI4OS-Europe, with the "License Clearance Tool" - LCT (https://lct.ni4os.eu/), aims to facilitate and automate the clearance of rights (copyright) for datasets, media, software that are to be cleared before they are publicly released under an open licence and/or stored at a publicly trusted FAIR repository. It will additionally allow the crowdsourced documentation of the clearance process. Main aspects of the tool include:
- Clearance not bound to the user that initiated the procedure, so it can be started and finished by different users.
- Potentially include crowdsourced clearance.
- Clearance metadata will be an open-source resource.
- Provides equivalence, similarity and compatibility between licenses if used in combination, particularly for derivative works.
Intended use
The intended use of the tool is to provide a guided approach for establishing the proper open-source licence required for the creation of a new (or synthetic) dataset, media, software etc. or for the re-use of existing unlicensed content. The procedure takes into account many potential data (media, software) managers (users initiating or completing a clearance procedure). Potential users may be researchers and research organisations.
Background: Legal aspects
The License Clearance Tool (LCT) comes as a response to the increased demand for providing technical solutions to address legal aspects in FAIR and ORDM. It is, thus, intended to support researchers to publish in FAIR/open modes. As such, the tool development has been preceded by extended legal search and analysis of most used licensing schemes. These have been put in a matrix, so as to allow the comparison "all with all" and unveil compatible and conflicting licenses. The first version of the tool provides guidance for existing standard open-source licenses only. The matrix, however, is continuously expanded and also includes custom licenses. The comparison of "standard to custom" and "custom to custom" poses a challenge for both: the analysis of the compatibility of licenses, but also the technical deployment of the solution. For this reason, the results of this activity are not included in the "proof of concept" version of the tool but will be implemented in the following ones.
Service Workflows
Two main workflows are foreseen. These are following the two possible usage scenarios the application covers and considered to be the most needed.
According to the first scenario, a user (data manager) aims to associate an appropriate open-source licence for existing content composed by different elements that are licensed separately or for derivative work by combining licenses from the originating licensed content and possibly non-licensed content. The associated workflow, Workflow I in the flowchart below, describes the procedure designed in the tool to answer the first usage scenario. The steps followed are:
- Start a new Rights Clearance Procedure. A user must initiate a new process for a specific content category. This process is bound to the content selected, but not the user, which means that a different user may finish the process (or alter it - forthcoming functionality).
- Existing dataset(s) or other content selection. These is the initial content that may be existing or future derivative work whose rights are to be cleared or require a compatible license.
- Identify corresponding licenses for each dataset/content. This step allows the association of each input dataset/content with a corresponding "license-in" selected from all available in a drop-down list.
- Compatibility processing. The tool's algorithm processes collected input to derive if an appropriate open-source license is available.
- Additional limitations (optional step). This step allows for introducing additional factors to the rights clearance procedure. This may allow or even require human intervention in future versions.
- Rights clearance report. The compatibility report for provided content and licences-in is produced, justified with appropriate links to a legal wiki (forthcoming functionality).
- Check incompatibility or restart the process (optional). If a compatible license option could not be found, the user may go back to review the compatible licenses of input content or re-initiate the procedure altering the given input.
- Final results are published. The procedure terminates and it cannot be re-initiated or altered.

|
The second usage scenario is a reverse rights clearance procedure, according to which a user (data manager) given the desired license-out verifies compatibility with existing licences-in (derivative work) or is given options for compatible licences-in for cases of existing unlicensed content. The steps followed for the associated workflow, Workflow II in the flowchart below, are:
- Start a new Rights Clearance Procedure. A user must initiate a new process for specific content. This process is bound to the content, but not the user, which means that a different user may finish the process (or alter it - forthcoming functionality).
- Desired license selection. A data manager selects the license-out from a drop-down list of available open-source licenses.
- Identification of available compatible licenses for dataset(s)/content licenses-in. The tool's algorithm processes license-out input to derive appropriate open-source license(s).
- Compatibility verification with actual datasets/content. The data manager may provide the actual content to verify compatibility with proposed licenses. This step is required for a complete and verified rights clearance procedure.
- Additional limitations (optional step). This step allows for introducing additional factors to the rights clearance procedure. This is May allow/require human intervention in future versions.
- Rights clearance report. The compatibility report for provided content and licences-in is produced, justified with appropriate links to the legal wiki (forthcoming functionality).
- Check incompatibility or restart the process (optional). If no compatible license option could be found the user may go back to review the compatible licenses or re-initiate the procedure an alter the provided input.
- Final results are published. The procedure terminates and it cannot be re-initiated or altered.

|
Overall Architecture

|
The License Clearance Application at its core contains a schema description that corresponds to the data that need to be filled in for processing by the clearance application. This description constitutes of a number of sections and questions, capturing all the needed information about the newly generated dataset and the existing exploited datasets (from which the new one is derived), including descriptive metadata and the available/desired licenses. It also defines the ordering of the sections and questions, any dependencies among them and the vocabularies used to fill in possible answers. This description will evolve with time and will be enhanced with additional data points. Aiming at being flexible, we map all the questions, the sections they belong to and the possible list of responses (if any) into a JSON (https://www.json.org/json-en.html) document stored in a NoSQL database MongoDB (https://www.mongodb.com/). This schema is retrieved by the front-end application, which dynamically creates a form-based wizard.
Components
The application is composed of two main services, the back-end service and the front-end application. The back-end service is responsible for implementing all the business logic of the application and providing all the necessary methods to the front-end one, for interacting with it and making available to the end-users the User Interface for clearing the license of a new content. The back-end service is composed of a number of different components, each one of them responsible for a different part of the system. Currently, these are:
- a user’s management component for managing the available users and their roles,
- the data management component for managing all the data and interacting with the data access layer,
- the configurator component for manipulating the schema description and
- the license validator component.
Data are stored either on a NoSQL database or to a relational one. The image besides presents the block diagram of the application. Some components have not been yet implemented but will be available during the next versions of it.
Schema Description
The structure of the schema description is presented below, using an example. Each section is described in a separate section.
Section Description
"id": "s01",
"name": "DataSet Information",
"description": "Information about the generated dataset",
"order": 1,
"mandatory": true,
"acceptsMultiple": false
The fields above describe a section. Each section contains:
- id: The id of the section. For internal use only
- name: A name to be displayed to the end-user
- description: A description to be displayed to the end-user
- order: The order of this section, compared to the other sections
- mandatory: If the section is mandatory or not
- acceptsMultiple: A field that indicates if the user could add multiple answers in this section.
Question Description
"id": "q013",
"name": "Dataset type",
"description": "Select the type of the datasource",
"sectionId": "s02",
"order": 7,
"mandatory": true,
"responseType": "DropDown",
"dependingQuestionId": "q011",
"public": true,
"vocabularyId": "v001"
Each question contains the following fields:
- id: The id of the question. For internal use only
- name: The name to be displayed to the end-user
- description: The description to be displayed to the end-user
- sectionId: The section it belongs to
- order: The order of the questions in the section it belongs to
- mandatory: If the question must be answered or not
- responseType: The type of the expected response. Currently, we support: ShortText, Text, Checkbox (for Boolean questions), FileUpload, * * DropDown (responses are limited to a specific list)
- public: If this response will be public or not
- vocabularyId: valid only for responseType: DropDown. An ID to the vocabulary from which the responses will be used.
- dependingQuestionId: if the responses for this question depend on the response to the previous question.
Vocabulary Description
"id":"v003",
"name":"Hardware Licenses",
"description":"Hardware Licenses",
"terms":[
{
"id":"v003_001",
"name": "CERN Open Hardware License"
},
{
"id":"v003_002",
"name": "Simputer General"
},
{
"id":"v003_003",
"name": "TAPR Open Hardware License"
}
]
Each vocabulary constitutes of an Id, a name and a description and a definite number of terms. Each term has an Id and a name/label.
Back-end service
A REST web service is implemented using the Java EE and the Spring Boot framework. The service offers an API (Application Programmatic Interface) with all the required methods for serving the application’s needs.
Front-end application
The front-end application (https://lct.ni4os.eu/) is implemented using Angular (https://angular.io/), a TypeScript-based open-source web application framework. In its first version, it offers a draft version of the license clearance form wizard. The wizard is created at runtime, supporting the dynamic schema description presented above.
The actual content of the wizard may vary depending on the configuration of the questions and the licensed validator, but the following screenshots, along with Workflow, illustrate the usage of LCT.
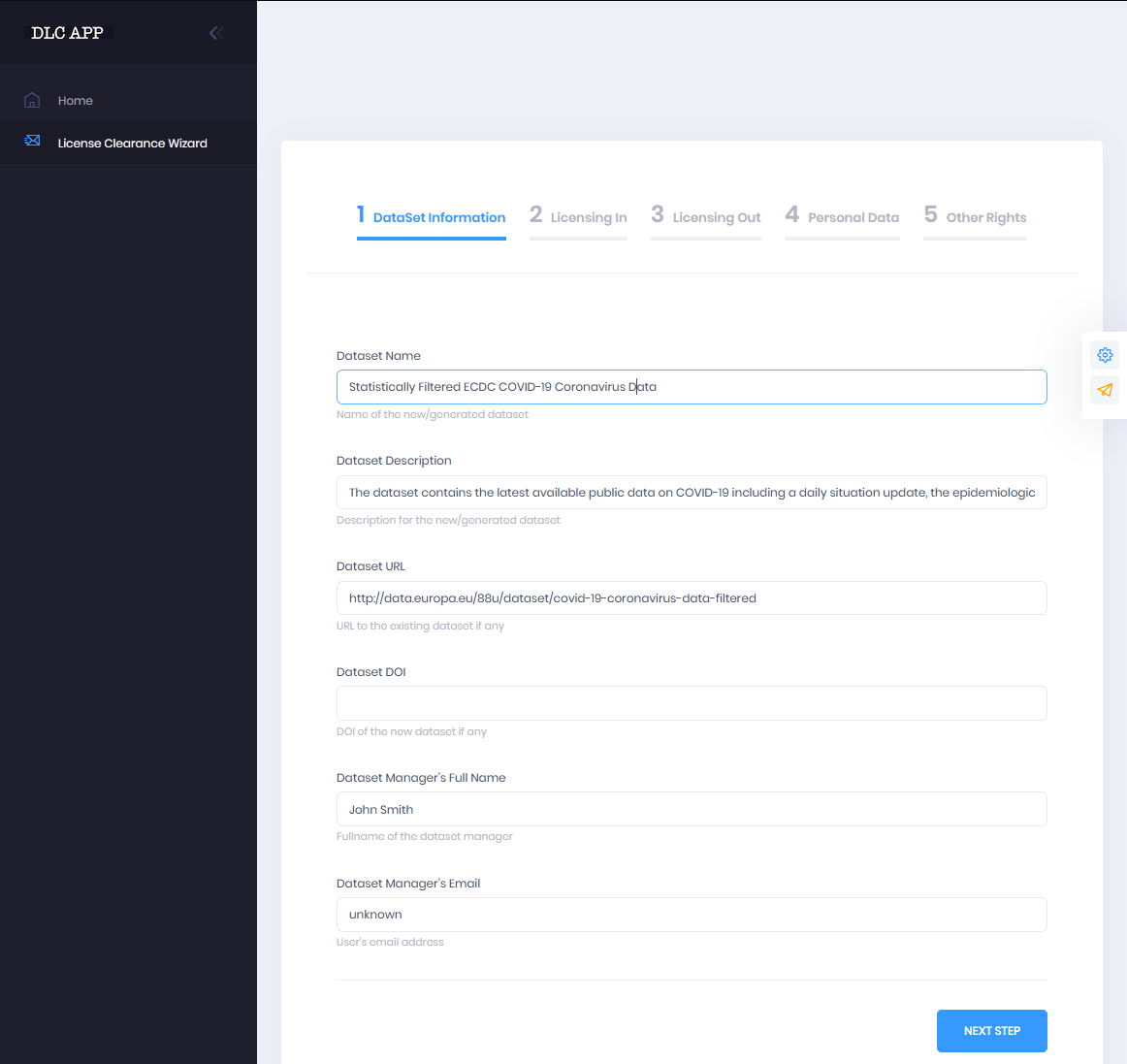
1 Dataset Information
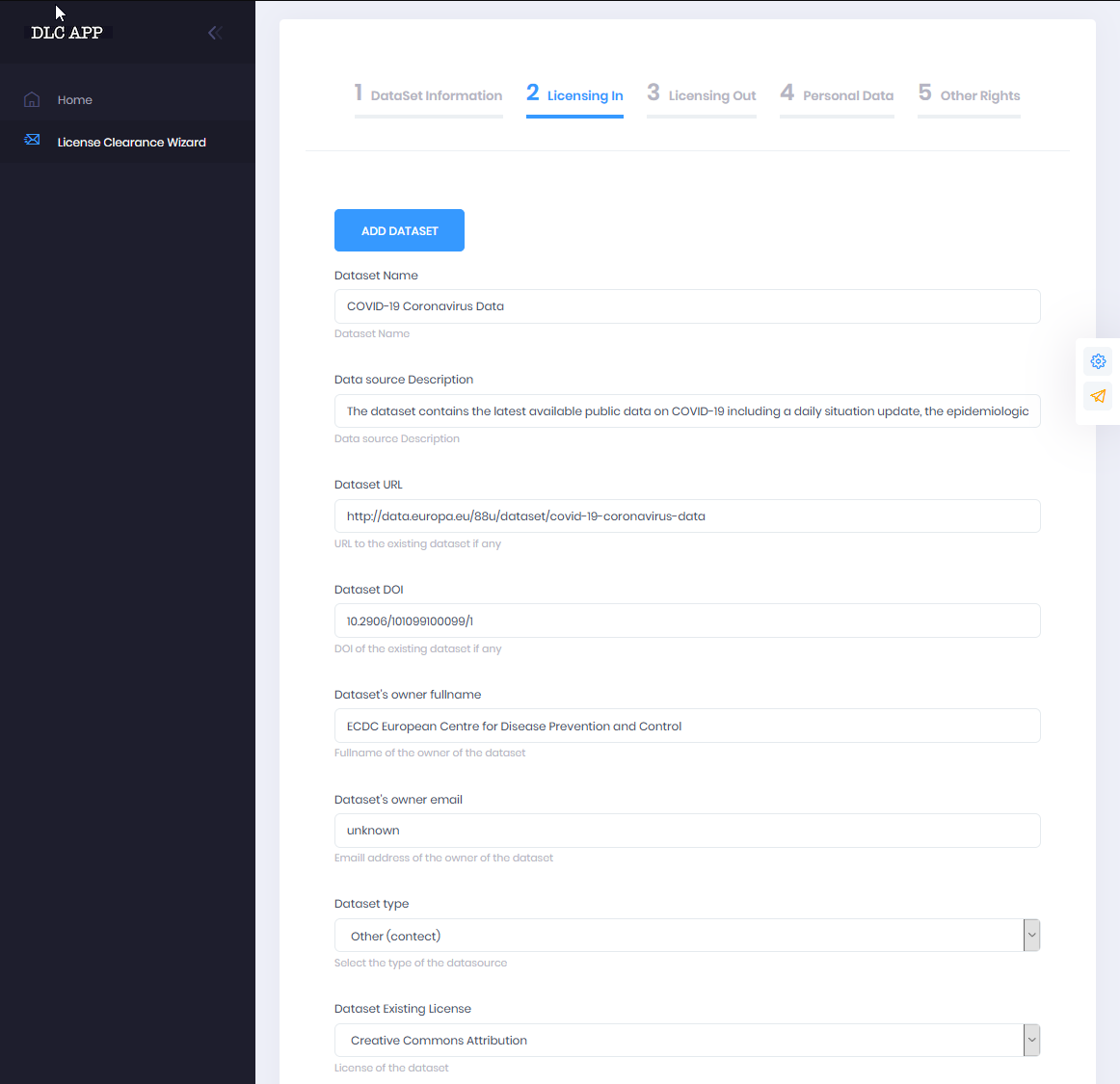
2 Licensing In
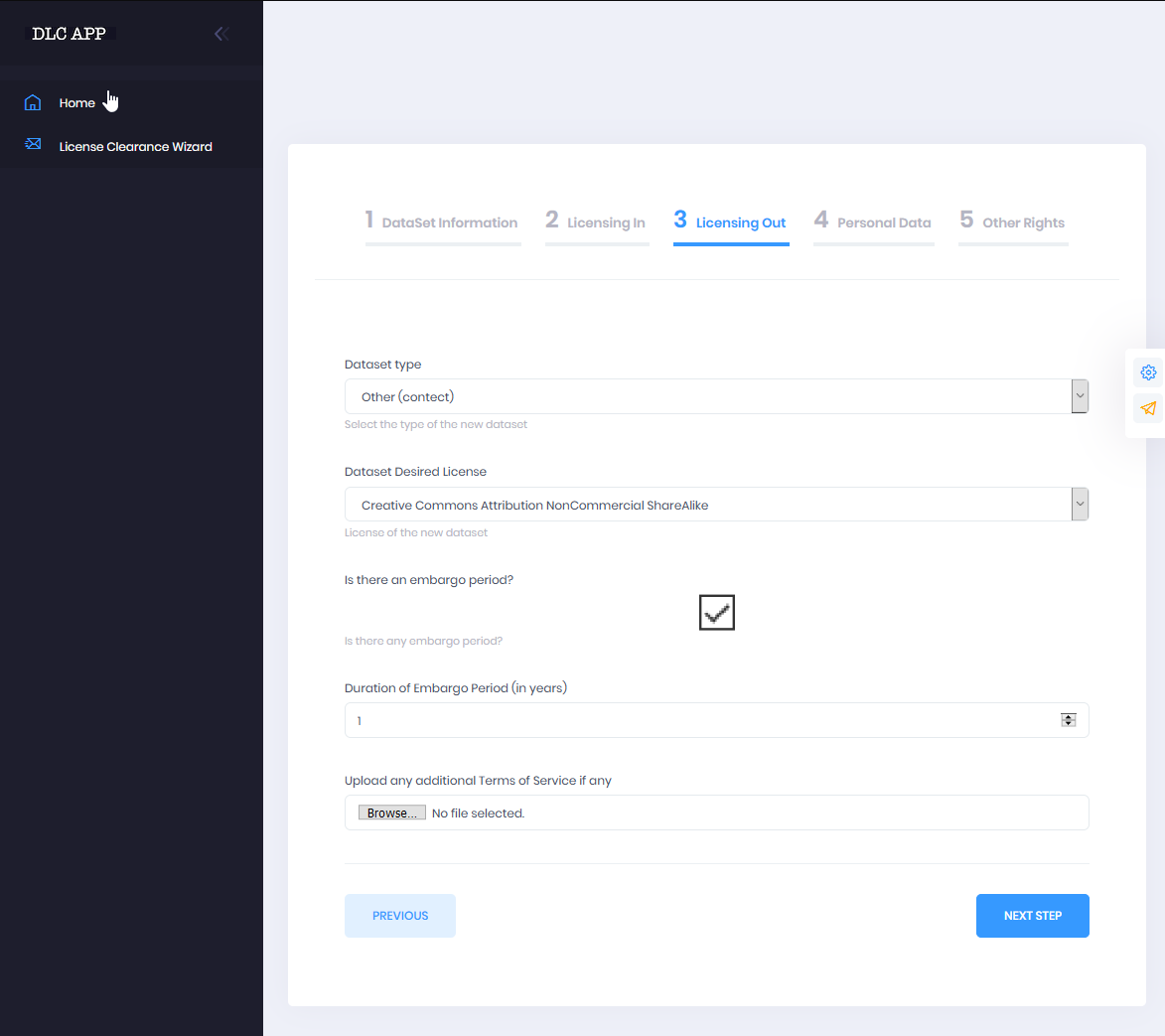
3 Licensing Out
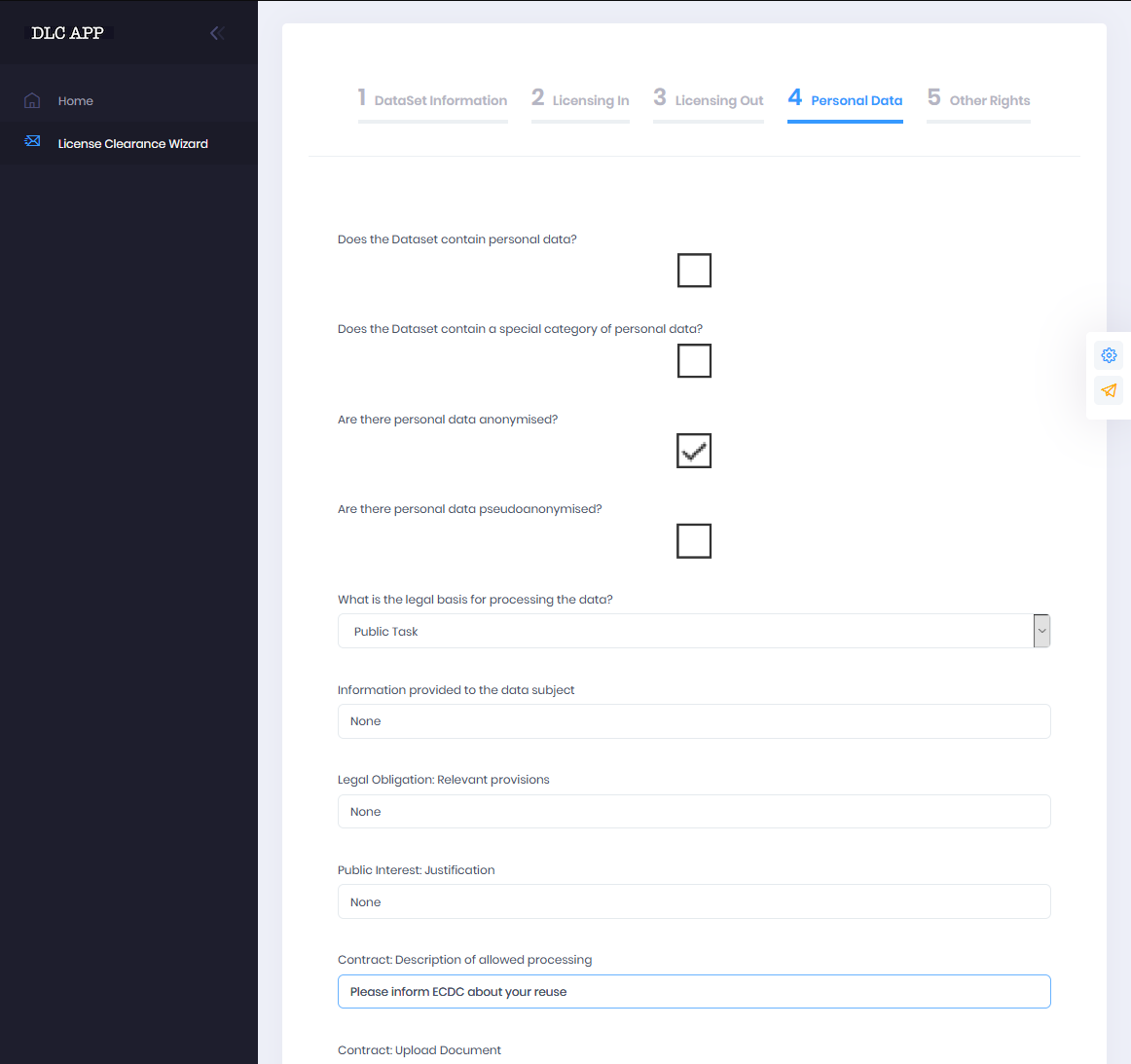
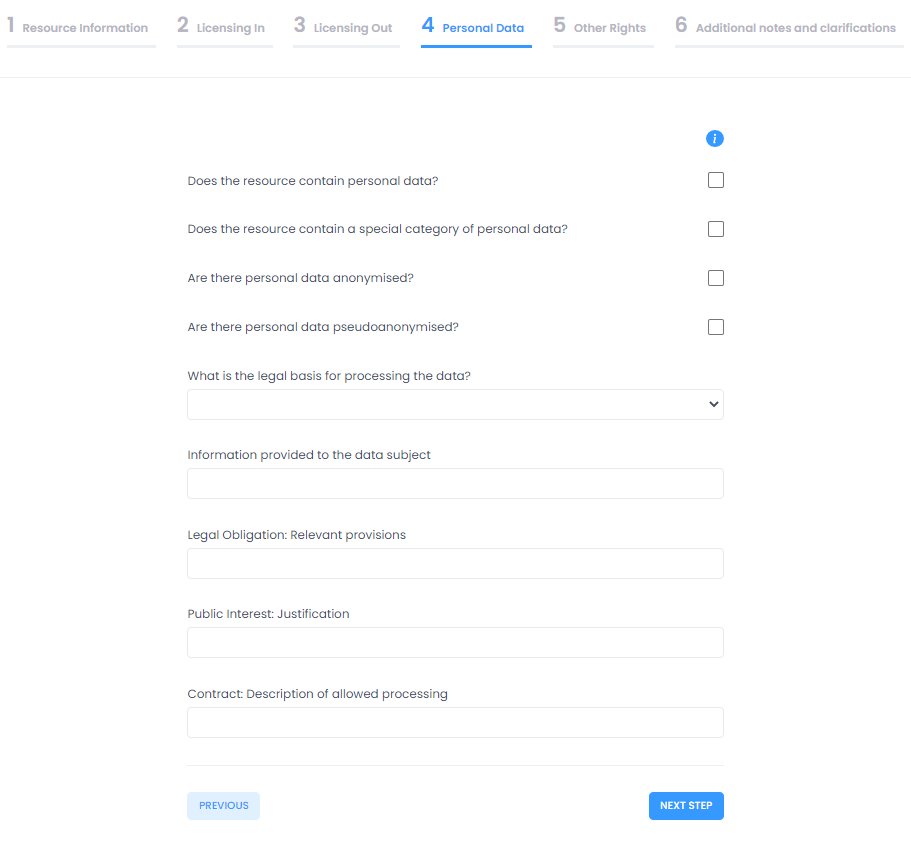
4 Personal Data
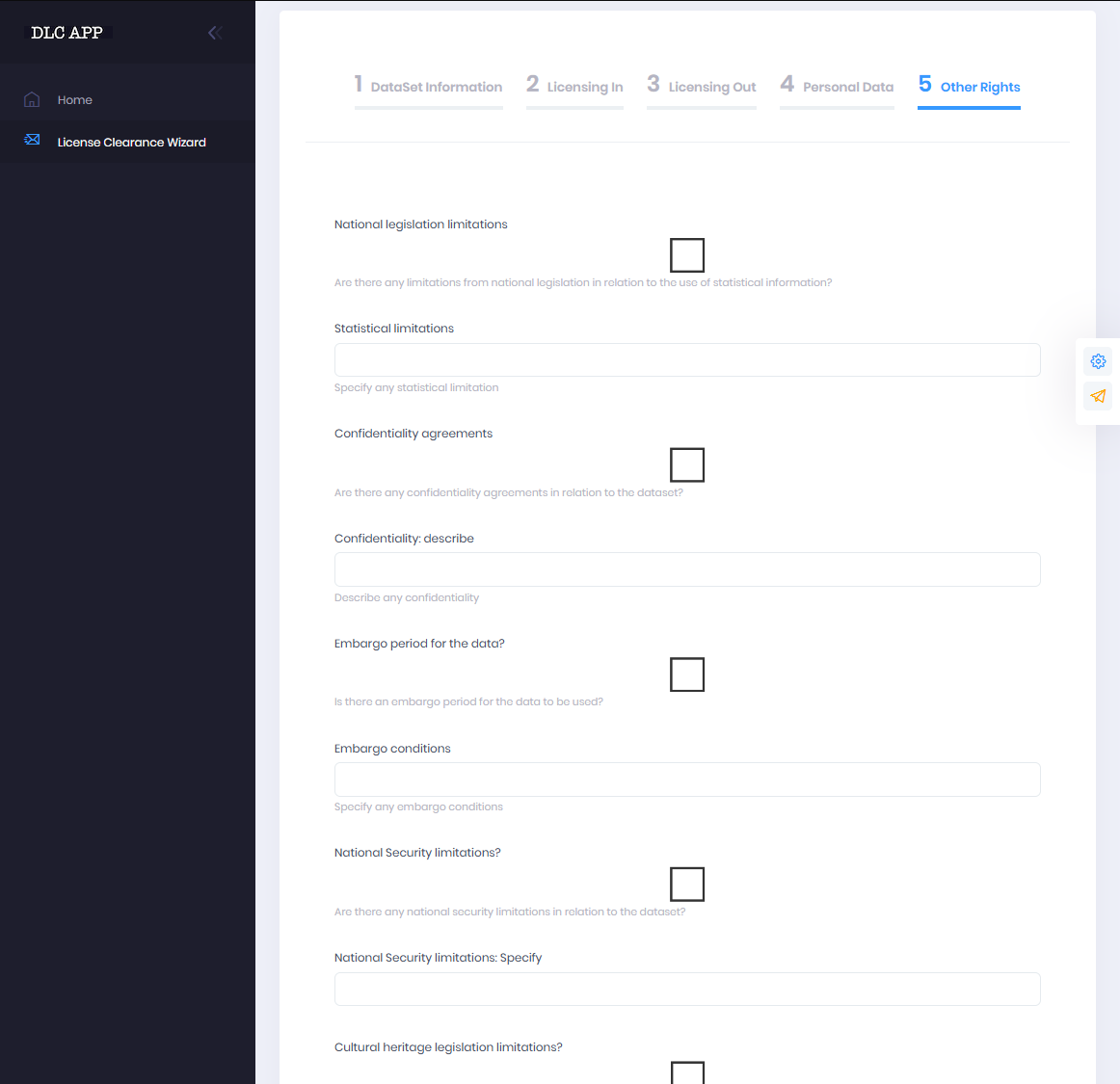
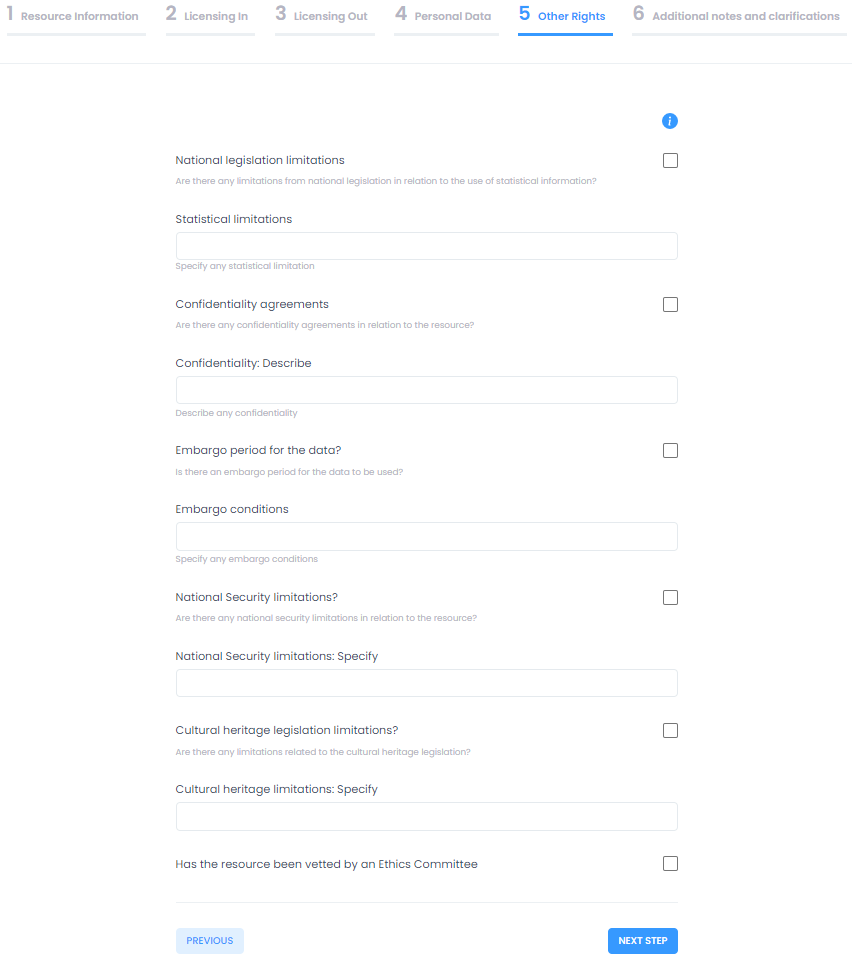
5 Other Rights





Usage

|
The application front-end provides a straight forward procedure in six steps presented as simple forms. Users have to select values from drop-down menus, enter required input in text fields, tick check-boxes or choose content to upload. Each input field should be filled top to bottom and the required input is described before the input field. Furthermore, there is an info-button present in each section (tabs 1-6) explaining what should be entered in each field. For further queries users may use the orange shortcut button "contact us" on the right side of the screen, which will allow them to quickly access the contact form to ask their questions. All fields marked with an asterisk at the end of their description are mandatory. If input is not provided for the mandatory fields the user is not allowed to proceed to next step of the process.
LCT landing page is where the user lands after visiting the tool's url at lct.ni4os.eu. User is given the option to continue as an authenticated user or to explore the tool as a guest. As a guest the user may experience the tool's full functionality, however no information and no part of the procedure is stored after the procedure completes. All provided information will be discarded after the final report is produced. As an authenticated user all parts of the procedure are kept in the user's history and the contents' under licensing clearance history. Login is enabled with version 3 (February 2021) and registered users may access and edit their profile pages and personal reporting history.
Next screen, Home of the wizard is where the user chooses the desired flow from the two available work flows explained in the Workflows. If the user chooses "I have a resource and want to clear derivate work licenses" will actually go through Workflow I and by choosing "I have a target license and want to understand license compatibility for initial resources" will follow Workflow II. The choice is made at the home screen where the users may return anytime by hitting the "home" link at the top left. At the moment users may follow the first choice representing Workflow I.

|
Depending on the choice, users are taken on either of the actual guided procedures for license clearance. The wizard for Workflow I starts by gathering information related to the resource to be cleared, Resource Information. Mandatory information to be provided is the resource type (data, software, audio, etc.), the name of the new/generated resource, a description for the new/generated resource, the full name of the resource manager and its email address. Next the wizard continues to the Licensing In area. This section provides information regarding the licenses under which are the different elements (subsets) of the resource and can accept any number of resources. The user may add as many resources as required here completing the fields name, type of the resource and its existing license and clicking on add resource to add each new resource.
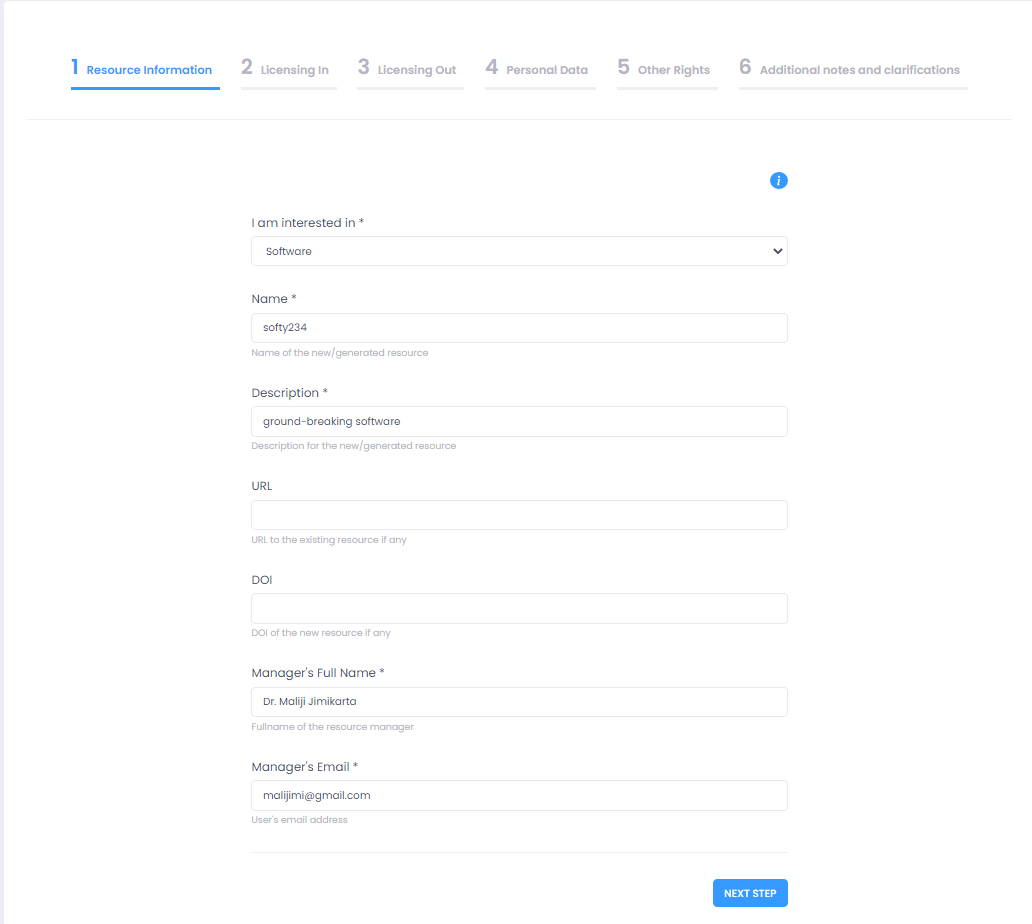
Resource Information
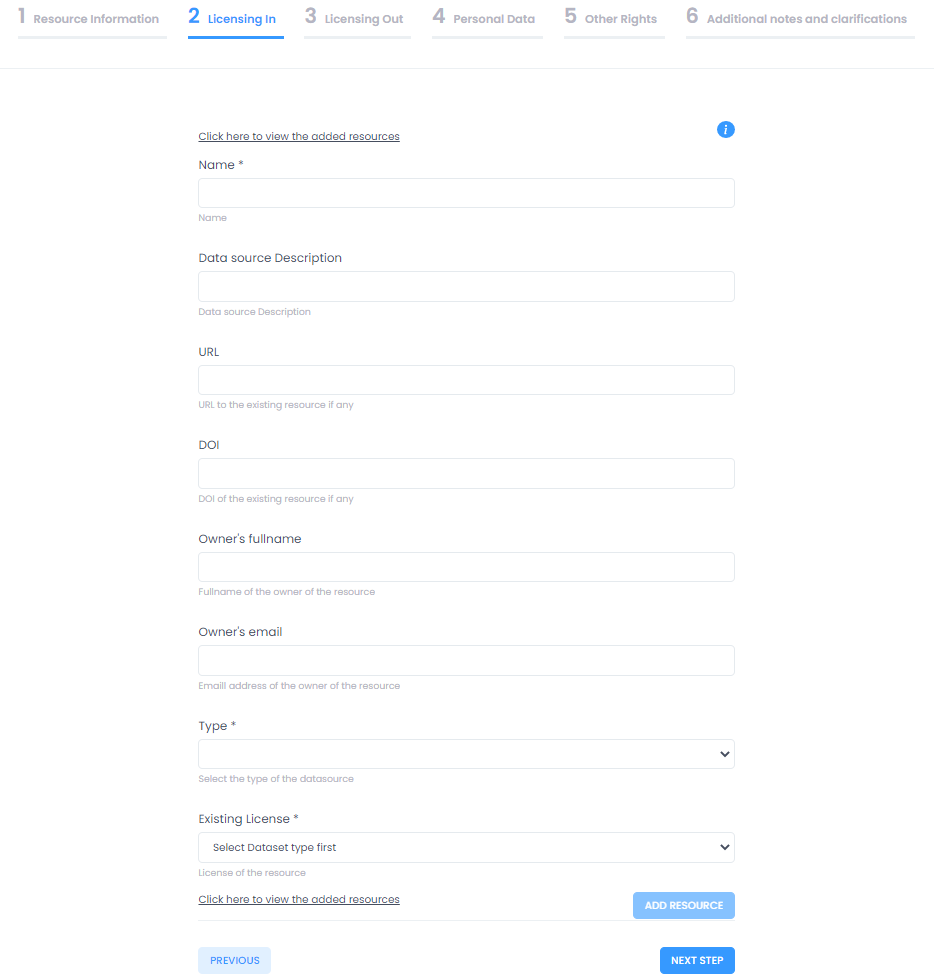
Licensing In
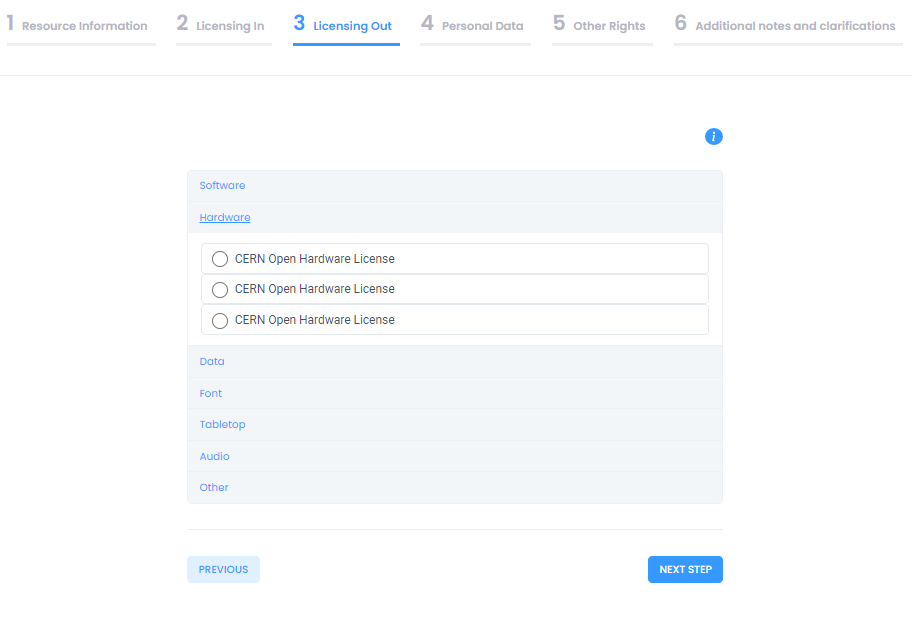
Licensing Out
Personal Data
Other Rights
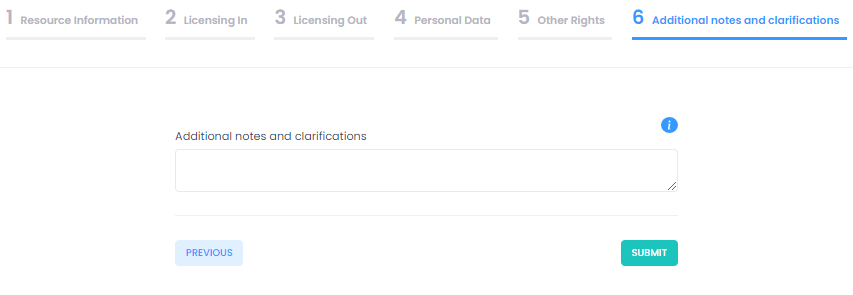
Additional notes and clarifications






Users may see a complete list of their added resources by clicking at the link "Click here to view the added resources" and make changes by deleting a resource from the table. When all desired resources have been added, clicking "Next" will take users to the next step Licensing Out.

|
The Licensing out section provides information regarding the types of licenses under which the resource will be made available on the basis of the compatibility calculation. Compatible licenses are presented in categories according to types (software, data, audio, etc.). Users have to make a licensing out choice to move to the next section. Sections 4 and 5 gather further information regarding the legal bases under which the resource may be lawfully processed and provide a check-list of other types of rights that should be cleared before the resource is released to further assist resource managers in the clearance procedure. The last section provides a means to gather other notes and clarifications regarding rights and permissions related to the resource and enable future human interaction particularly concerning specialized legal advice. At this point users may hit "Submit" to trigger the creation of the output report, which may be downloaded once it has been generated by the platform. A sample report may be seen below:

LCT report page 1

LCT report page 2
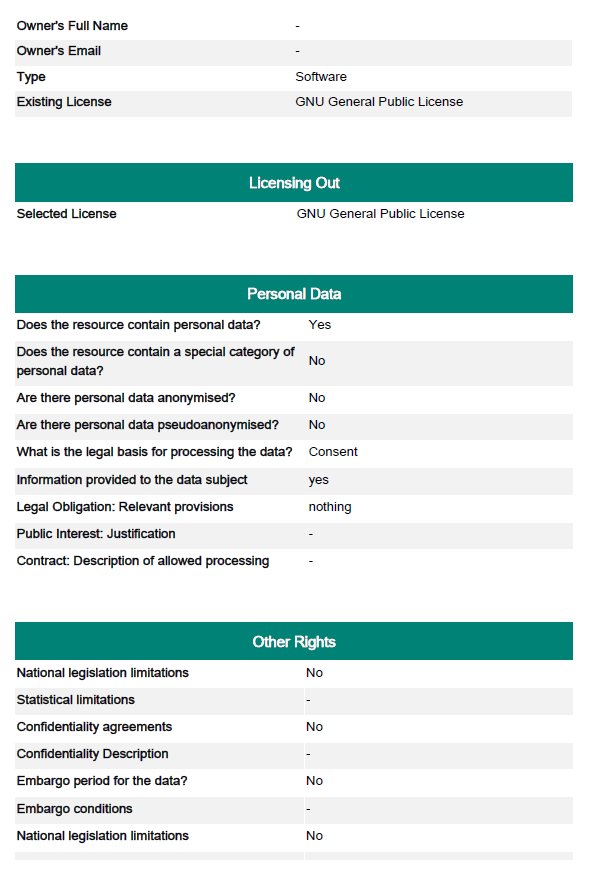
LCT report page 3



A user profile page is available for logged in users, showing the information received by the NI4OS-Europe AAI service. Users have the ability to edit/add non-essential information in their profile page, which is information that is not associated with the AAI mechanism. Clearances history is also available for logged in users, providing a list with previous wizard runs along with the produced reports. Users may download previous reports or access the wizard with the previously saved data and make modifications.
 
|
Version features
Version 1, June 2020:
- Initial version provides a proof-of-concept workflow.
- Will initially provide guidance for existing standard open-source licenses only.
- General Privacy policy is formulated
Version 2, September 2020:
- Name change to match the wider purpose of the tool.
- Production server reached at https://lct.ni4os.eu/
- Contact/issues form.
- Documentation, questions shortcut buttons.
- New branding logo.
- Updated Privacy Policy.
- Added terms of use.
- Reworked back-end compatibility algorithm.
- Reworked user interface.
- Added ability to input free text notes (Tab 6).
- Mandatory fields validation.
- Create e-mail service
Version 3, February 2021:
- Added AAI mechanism utilising NI4OS-Europe AAI
- Added registered users profile pages
- User profile page may be edited.
- Reporting history for each registered user is automatically saved.
- Older reports for registered users may be accessed, loaded and edited and produced reports may be re-downloaded.
- Cookies policy and consent has been added.
- Privacy policy has been updated.
Team
Vassilis Kifonidis, Panagiota Koltsida, Christos Liatas, George Panagiotopoulos, Panoraia Spiliopoulou, Eleni Toli